Next: Parallelization of implicit propagation Up: Parallel implementation aspects Previous: Parallel implementation aspects
The mapping of subdomains on processors should be chosen so as to distribute
the computational load as equally as possible and to minimize the communication
cost. Intuitively, it will be clear that we have to allocate contiguous blocks
of equal numbers of grid points on each processor. However, in the context of
SWAN applications to coastal areas, some difficulties arise. Firstly, wet and
dry grid points may unevenly distributed over subdomains while no computations
have to be done in dry points. Secondly, an unbalanced partition may arise
during the simulation due to the tidal effect (dry points become wet and vice
versa). In such a case, one may decide to adapt the partition such that it is
balanced again (so-called dynamic load balancing). Finally, most end-users are
not willing to determine the partitioning themselves, thus automatic support
for partitioning the grids is desirable.
In the present study, two well-established partition methods are applied. The
first is called stripwise partitioning in which the computational grid is cut
along one direction, resulting in horizontal or vertical strips. The choice of
cutting direction depends on the interface size of the strips which should be
minimized. However, the communication volume, which is related to the total size
of the interfaces, can be further reduced by means of recursive application of
alternately horizontal and vertical bisection. This is known as Recursive
Co-ordinate Bisection (RCB). Further details on these techniques and an overview
on grid partitioning can be found, e.g. in Fox (1988) and Chrisochoides et al. (1994).
.
Within SWAN, the grid partitioning is carried out automatically on wet grid points
only. The size of the subdomain equals the total number of wet points divided by
the total number of subdomains. The implementation of a stripwise partitioning is
as follows. First, an empty strip is created. Next, assign point-by-point to the
created part until the size of that part has been reached. Thereafter, verify
whether non-assigning wet points remain in the current strip. If so, these points
will be assign to the same part too, otherwise create next empty strip. As a result,
all strips have straight interfaces and include approximately the same number of wet
grid points. Moreover, experiences with SWAN simulation have shown that the amount
of computations in each wet grid point remains more or less constant during the
simulation and hence, there is no need for dynamic load balancing.
A final remark has to be made considering grid partitioning. The above described
methodology does not seem to have been implemented in spectral wave models before.
In Tolman (20020, another way of distributing data over the processors is discussed:
each 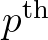 wet grid point is assign to the same processor with
wet grid point is assign to the same processor with 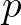 the total
number of processors. The requirement of equal numbers of wet grid points per processor
is provided automatically. However, it is impossible to compute the spatial wave
propagation in an effective manner. The only alternative is to gather data for all
grid points in a single processor before the calculation is performed. This will
require a full data transpose, i.e. rearranging data distribution over separate
processors. It is believed that this technique requires much more communication between
processors than domain decomposition and therefore less suitable for SWAN.
the total
number of processors. The requirement of equal numbers of wet grid points per processor
is provided automatically. However, it is impossible to compute the spatial wave
propagation in an effective manner. The only alternative is to gather data for all
grid points in a single processor before the calculation is performed. This will
require a full data transpose, i.e. rearranging data distribution over separate
processors. It is believed that this technique requires much more communication between
processors than domain decomposition and therefore less suitable for SWAN.
The SWAN team 2026-03-13